



Jak to dziaéa?
Czy pamiátasz takie programy, jak Norton Commander, Turbo Pascal czy mks_vir? Dzisiaj jest to jué¥ cyfrowa archeologia. Te programy, za sprawá pewnych trikû°w, umoé¥liwiaéy wyéwietlenie informacji w atrakcyjnej, jak na tamte czasy, szacie graficznej, przy wykorzystaniu bardzo ubogich zasobû°w sprzátowych. Dziaéaéy one w tzw. trybie tekstowym, czyli wyéwietlaéy tylko i wyéá cznie litery, cyfry oraz rû°é¥ne kreski, strzaéki i inne symbole przygotowane przez producenta karty graficznej.
Wszystkie symbole musiaéy mieá te same wymiary, a najczáéciej stosowaéo siá znaki o wysokoéci 16 pikseli i szerokoéci 8 pikseli. Jeé¥eli monitor miaé rozdzielczoéá 640û480 px, to moé¥na byéo na nim wyéwietliá symbole zorganizowane w 80 kolumn i 30 wierszy.
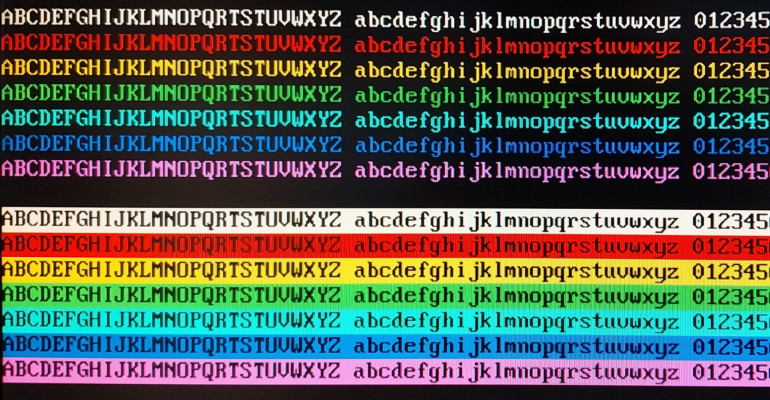
Do dyspozycji jest 256 symboli, poniewaé¥ tyle moé¥na zakodowaá w 8-bitowej zmiennej, czyli w jednym bajcie. Przykéad takiego zestawu symboli, zwanego stroná kodowá , widzimy na rysunku 2. Istnieje dué¥o rû°é¥nych stron kodowych, obejmujá cych znaki diakrytyczne w wielu rû°é¥nych jázykach i innych alfabetach.
We wczesnych systemach komputerowych kolory byéy 4-bitowe. Trzy bity na skéadowe poszczegû°lnych kolorû°w RGB, ktû°re pozwalaéy uzyskaá osiem kolorû°w: czerwony, é¥û°éty, zielony, cyjan, niebieski, magentá, biaéy i czarny. Czwarty bit pozwalaé rozjaéniá kolor, co w rezultacie dawaéo 16 rû°é¥nych barw.
Kaé¥dy symbol ma pierwszy plan (foreground) oraz téo (background). Moé¥na im przypisaá rû°é¥ne kolory, jednak w obrábie jednego znaku moé¥e byá wybrana tylko jedna barwa pierwszego planu i jeden kolor téa. Cztery bity kodowaéy wiác kolor pierwszego planu, a kolejne cztery ã kolor téa znaku, czyli wystarczyé jeden bajt, aby zapisaá wszystkie te informacje.
Dochodzimy do wniosku, é¥e za kaé¥dy znak wyéwietlany na monitorze odpowiedzialne byéy dwa bajty. Pierwszy ustalaé, jaki znak ma byá pokazany, a drugi decydowaé o kolorach. Zatem jeé¥eli mamy 80 kolumn i 30 wierszy, to razem otrzymujemy 2400 znakû°w ã czyli potrzebujemy 4800 bajtû°w. To zaskakujá co maéo jak na obraz o rozdzielczoéci 640û480 px i 4-bitowej kolorystyce. Gdybyémy chcieli taki obraz przechowywaá w pamiáci jako bitmapá, to potrzebowalibyémy jué¥ 153 600 bajtû°w, czyli 32 razy wiácej!
WãMachXO2-1200 mamy do dyspozycji siedem blokû°w EBR o pojemnoéci 1 kB kaé¥dy, zatem potrzebujemy piáá takich blokû°w na pamieá RAM odpowiedzialná za przechowywanie tekstu i koloru ã dwa kolejne zostaná nam do innych celû°w.
Zastanû°wmy siá teraz nad czcionká , poniewaé¥ ona také¥e musi byá zapisana w pamiáci. Zapewne jué¥ domyélasz siá, do czego ué¥yjemy pozostaéych dwû°ch blokû°w EBR. Zobacz rysunek 3, na ktû°rym zaprezentowano sposû°b zapisu jednego znaku w pamiáci. Symbole majá rozmiar 16 pikseli w pionie i 8 pikseli w poziomie. Te liczby sá nieprzypadkowe i wynikajá ze sprytnej optymalizacji ã rozdzielczoéá pozioma to osiem pikseli, dlatego é¥e w jednym bajcie jest wéaénie tyle bitû°w.
Kaé¥dy bit tego bajtu odpowiada zatem za jeden piksel. Stan wysoki bitu oznacza, é¥e zostanie on wyéwietlony kolorem pierwszego planu, a stan niski spowoduje, é¥e bádzie miaé taki kolor, jaki wybrany zostaé dla téa.
Caéy znak tworzy 16 bajtû°w i ta liczba rû°wnieé¥ nie jest przypadkowa ã wszak to czwarta potága dwû°jki (24=16), a 16 kombinacji moé¥emy zapisaá na czterech bitach. Kaé¥dy symbol ma swû°j adres w pamiáci, a poniewaé¥ kaé¥dy z nich wykorzystuje dokéadnie 16 bajtû°w, adres poczá tku znaku (tzn. zerowego bajtu znaku) moé¥emy bardzo éatwo obliczyá wzorem
Adres=16ôñKodASCII
gdzie KodASCII to numer znaku od 0 do 255. Jednak wcale nie musimy wykonywaá é¥adnego mnoé¥enia! W FPGA operacje mnoé¥enia i dzielanie na liczbach bádá cych potágami dwû°jki to de facto... przestawianie bitû°w. Skoro mamy 256 znakû°w w pamiáci, to potrzebujemy 8 bitû°w, by zapisaá tá liczbá (28=256) ã umieszczamy je na bardziej znaczá cych pozycjach, a numer jednej z szesnastu linii bitmapy czcionki umieszczamy na czterech méodszych bitach. W ten sposû°b powstaje nam 12-bitowy adres w pamiáci.
212=4096 ã potrzebujemy wiác czterech blokû°w EBR, aby mû°c pomieéciá caéá czcionká. Jednak jest z tym pewien problemãÎ pozostaéy nam tylko dwa bloki do dyspozycji. No cû°é¥, albo weé¤miemy ukéad FPGA o wiákszej pamiáci, albo obetniemy plik czcionki i zadowolimy siá znakami od 0 do 127, czyli wszystkimi literami, cyframi, interpunkcjá , znakami kontrolnymi i niektû°rymi znakami diakrytycznymi. Wybraéem tá drugá opcjá, czyli 5 blokû°w EBR przeznaczyéem na pamiáá RAM tekstu i koloru, a 2 bloki EBR bádá funkcjonowaá jako pamiáá ROM czcionki. Kody znakû°w ASCII bádá nie 8-bitowe, jak to zwykle bywa, lecz tylko 7-bitowe.
Zastanû°wmy siá teraz, w jaki sposû°b bádziemy dostarczaá dane do pamiáci RAM tekstu i koloru. W zaéoé¥eniu nasz terminal ma byá poéá czony z komputerem, zatem najproéciej bádzie wyposaé¥yá go w odbiornik UART (nadajnik nie jest potrzebny, bo wystarczy nam komunikacja jednokierunkowa). Musimy opracowaá jakié prosty protokû°é komunikacji. Zobacz rysunek 5, na ktû°rym pokazano dwie ramki transmisji.
Najstarszy bit z przesyéanego bajtu decyduje o znaczeniu pozostaéych bitû°w. Zero oznacza, é¥e pozostaée bity [6:0] to kod ASCII znaku do wyéwietlenia, zaé jedynka na tej pozycji ã é¥e bity [6:4] to kolor znaku, a pole [2:0] to kolor téa.
Po odebraniu bajtu tekstu przez interfejs UART odpowiadajá cy mu znak ma zostaá natychmiast wyéwietlony na ekranie, na pozycji aktualnie wskazywanej przez kursor, po czym kursor zostaje przesuniáty o jedná pozycjá w prawo lub na poczá tek kolejnej linii. Domyélnie terminal bádzie wyéwietlaé biaée znaki na czarnym tle. Odebranie bajtu koloru spowoduje zapisanie do rejestru kolorû°w nowych ustawieé i bádá one dotyczyéy kolejnych odebranych bajtû°w tekstu ã tak déugo, aé¥ zostanie przeséany kolejny znak koloru.
Taki sposû°b komunikacji jest bardzo wygodny ze wzgládu na kompatybilnoéá z rû°é¥nymi systemami nadrzádnymi. Terminal bádzie mû°gé prezentowaá znaki pochodzá ce od dowolnego nadajnika UART, a jeé¥eli nie obséuguje on kolorû°w, to terminal wyéwietli wszystko biaéá czcionká na czarnym tle.



















