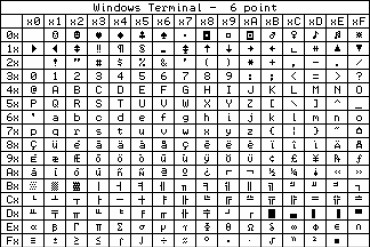
cOtóż pakiet Arduino IDE wykorzystuje kodowanie zwane UTF-8. Jeśli chcemy wyświetlić na konsoli ekranu znaki spoza zestawu ASCII, to musimy wykorzystać kod UTF-8. Gorzej jest w drugą stronę, a także przy wykorzystaniu znakowego wyświetlacza LCD, gdzie mamy kod ASCII i określone dodatkowe znaki. Mamy do czynienia z różnymi sposobami kodowania napisów, a dla początkujących jest to czarna magia.
W poprzednich artykułach „Wokół Arduino” omówiliśmy siedmiobitowy kod ASCII. Wiemy, że do zakodowania podstawowych znaków języka angielskiego wystarczy siedem bitów, co daje 128 kombinacji zer i jedynek. Podstawową jednostką w informatyce jest bajt, czyli osiem bitów i wiemy już, jak dodatkowe 128 kombinacji może kodować różne znaki narodowe (litery) i inne znaki graficzne. Dowiedzieliśmy się też o poważnych problemach z tak zwanymi stronami kodowymi. Potrzebne okazało się jeszcze inne rozwiązanie, pozwalające kodować jeszcze więcej znaków. Tym rozwiązaniem jest...