Jedna sprawa to teksty, mówiąc w uproszczeniu: napisy składające się z liter (ale też innych znaków). Druga sprawa to liczby. I tu mamy dwie dodatkowe odrębne kwestie. Jedna to sprawa liczb „mniejszych, większych, ułamkowych” oraz sposób ich reprezentacji w komputerze za pomocą zer i jedynek. W grę wchodzą tu typy zmiennych (m.in. byte, char, int, long, float, double) i tym bardzo ważnym zagadnieniem zajmiemy się w oddzielnych artykułach. A teraz przyjmujemy tylko, że w komputerze/procesorze mamy rozmaite liczby, a wszystkie w sumie są mniejszymi i większymi zbiorami zer i jedynek.
W tym artykule zajmiemy się drugim aspektem związanym z liczbami. Otóż teraz nie interesują nas szczegóły, jak liczby są reprezentowane/kodowane w procesorze i jego pamięci, tylko interesuje nas dwustronna komunikacja, przesyłanie, przekazywanie na drodze procesor–człowiek (człowiek–procesor) zarówno wartości liczbowych, jak też napisów – tekstów.
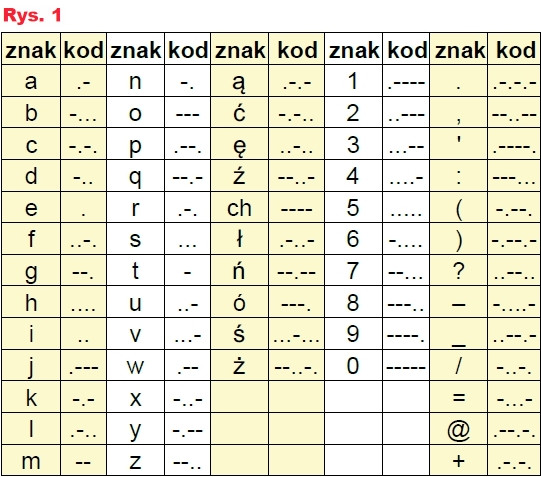
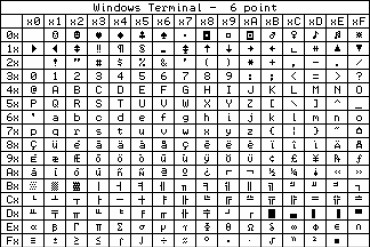
Procesor najczęś...