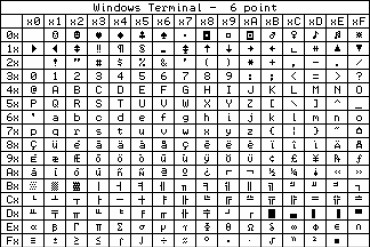
Zacznijmy od tego, ze na wspomnianej przed miesiącem pożytecznej stronie znajdziemy tylko numery unikodu, ale nie ma tam informacji o kodach UTF-8. Także we współczesnych komputerach wykorzystywany jest unikod i w edytorze tekstu można łatwo sprawdzić numer unikodu danego znaku. Rysunek 5 to zrzut z ekranu podczas pracy z LibreOffice (OpenOffice). Ale też nie ma tam informacji o kodowaniu UTF-8.
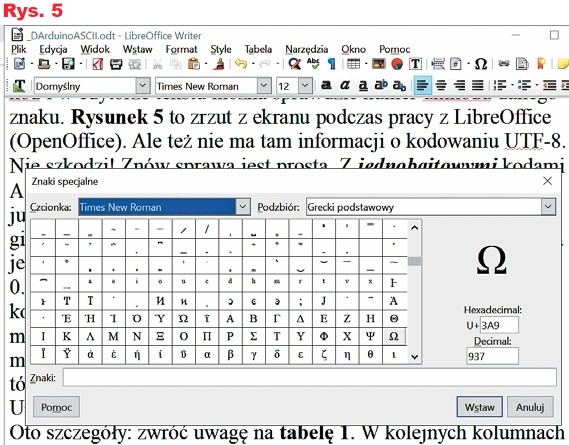
Nie szkodzi! Znów sprawa jest dość prosta. Z jednobajtowymi kodami ASCII w ogóle problemu nie ma. W kodach dwubajtowych, jak już wiemy, trzy pierwsze bity w pierwszym bajcie i dwa w drugim są zawsze te same. Z szesnastu bitów pozostaje jedenaście, a jedenaście bitów pozwala zapisać liczby dwójkowe w zakresie 0...2047, czyli w zapisie dwójkowym 0...11111111111, szesnastkowo 0...7FF.
Nietrudno się więc domyślić, że w dwóch bajtach można zakodować znaki unikodu o numerach do U+7FF, natomiast dla wyższych numerów potrze...