To dało mi do myślenia, dlaczego by nie obserwować, badać i zbierać odgłosy zwierząt i ptaków, wydobywać emocje z tych dźwięków i stworzyć urządzenie, które tłumaczyłoby ich język na nasz i vice-versa? To byłoby niesamowite! W oparciu o badania naukowców, istnieje kilka zbiorów danych open source dotyczących metod komunikacji w przyrodzie, dostępnych do użytku dla każdego.
Tak więc, wykorzystując te zbiory danych open source, można opracować i wytrenować model języka maszynowego (ML), który rozumie emocje w różnych odgłosach zwierząt i odpowiednio je sklasyfikuje. Projekt pokazuje jak wdrożyć model ML do tłumaczenia języka ludzkiego na język natury i z powrotem, umożliwiając efektywną komunikację.
Czyż nie brzmi to niesamowicie? Tak więc, nie tracąc czasu, rozpocznijmy naszą piękną podróż.
Przygotowanie zbiorów danych
ML musi zostać zasilony odpowiednimi danymi dotyczącymi dźwięków i emocji. Można pobrać różne zestawy danych open source różnych ptaków i zwierząt dostępne online, takie jak dźwięki wydawane przez słonia w celu komunikowania ruchu, miłości, troski, gniewu itp.
Po pobraniu takich dźwięków zwierząt, skompiluj je w zestawy danych do trenowania modelu ML. Można użyć do tego celu takich narzędzi jak Tensorflow, Edge Impulse, SensiML, Teachable Machine i wiele innych. W projekcie użyto Edge Impulse.
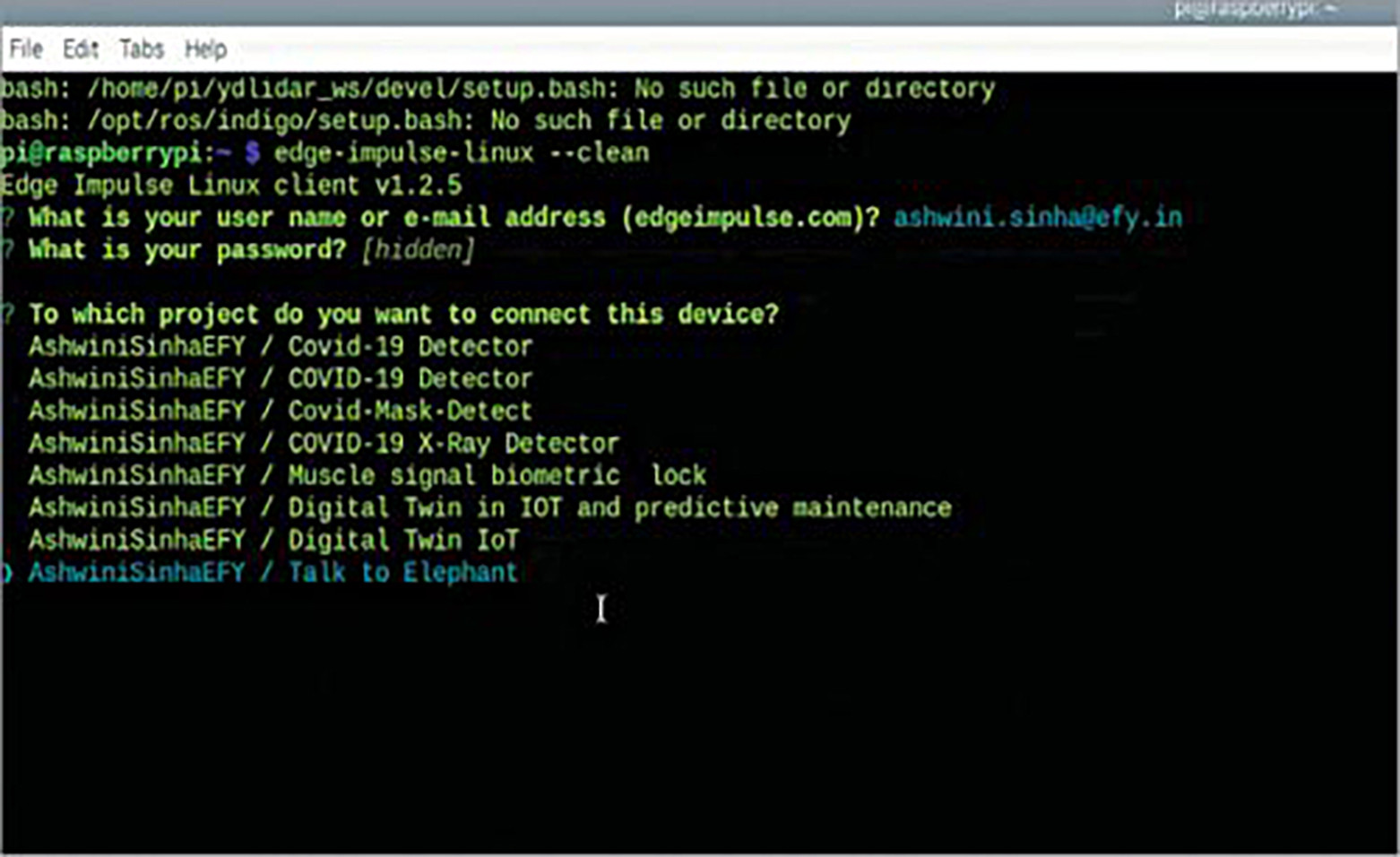
Otwórz terminal Raspberry Pi i zainstaluj zależności Edge Impulse. Następnie używając poniższych komend, utwórz nowy projekt o nazwie Fauna Translator:
curl -sL https://deb.nodesource.com/
setup_12.x | sudo bash –
sudo apt install -y gcc g++ make build-essential nodejs sox gstreamer1.0-tools gstreamer1.0-plugins-good gstreamer1.0-plugins-base gstreamer1.0-plugins-base-apps
npm config set user root && sudo npm install
edge-impulse-linux -g –unsafe-permPotem, połącz projekt Raspberry Pi z Edge Impulse używając Edge-impulse-linux
Następnie otwórz terminal i wybierz nazwę projektu, po czym otrzymasz adres URL do podawania zbiorów danych. Za pomocą tego adresu należy wprowadzić przechwycone odgłosy zwierząt i odpowiednio je oznaczyć na podstawie różnych emocji (zły, zadowolony, głodny) lub wyrażeń ("Chodźmy", "Kocham Cię").
Uwaga: Przed przystąpieniem do przechwytywania danych dźwiękowych należy założyć moduł AIY Voice na Raspberry Pi, jak pokazano na fotografii 1.

Model ML
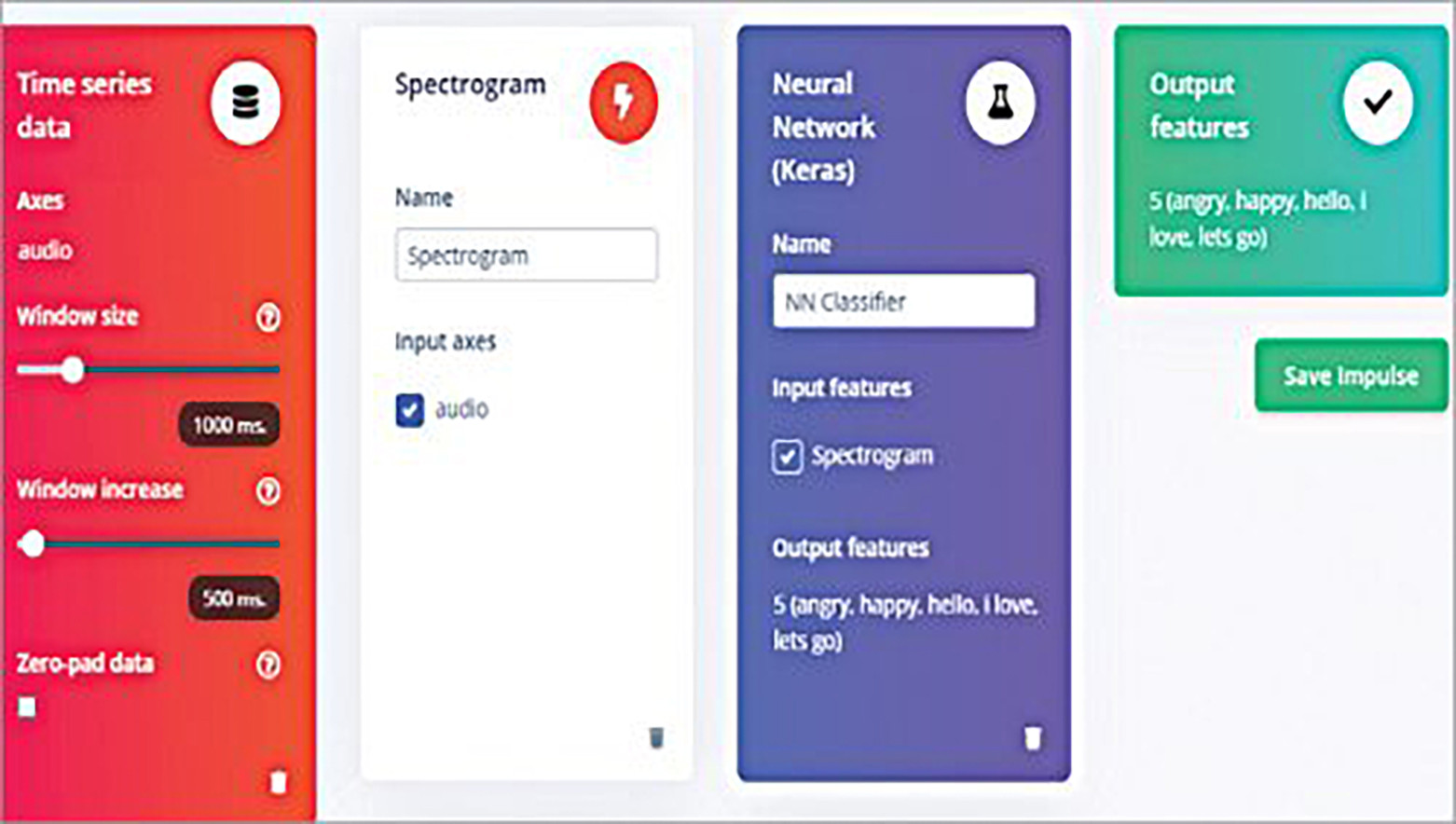
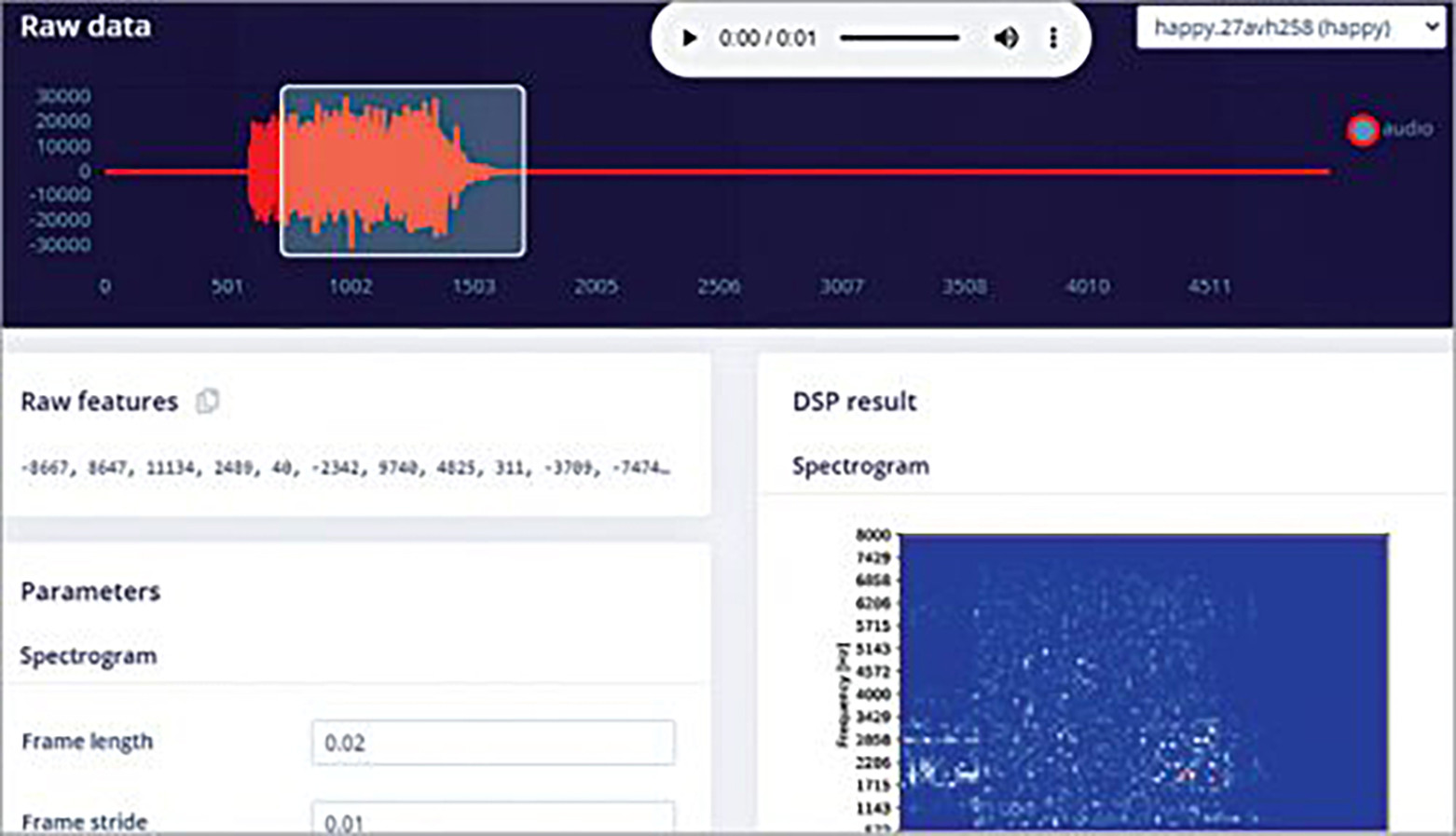
Wybierz bloki uczenia i przetwarzania do trenowania modelu ML. W tym przypadku użyto Spectrogram dla bloku przetwarzającego i Keras dla bloku uczącego. Używając ich, wyodrębnij różne parametry audio do szkolenia modelu ML, aby uczyć model z zestawów danych. Następnie przetestuj model i udoskonalaj go, aż będziesz zadowolony z jego dokładności.
Aby wdrożyć model ML, przejdź do opcji deploy i wybierz płytkę Linuksa. Zainstaluj go i sklonuj SDK z edge impulse.
sudo apt-get install libatlas-base-dev libportaudio0 libportaudio2 libportaudi ocpp0 portaudio19-dev
pip3 install edge_impulse_linux -i https://pypi.python.org/simple
pip3 install edge_impulse_linux
git clone https://github.com/edgeimpulse/linux-sdk-pythonKodowanie
Utwórz plik .py o nazwie animal_translate i zaimportuj espeak w kodzie Pythona, który tłumaczy odgłosy zwierząt tak, aby ludzie mogli je zrozumieć. Utwórz warunek if do sprawdzania dokładności emocji obecnych na wyjściu modelu ML. Jeśli zostanie wykryta dokładność wyjściowa 98% lub więcej dla danej etykiety to znaczy, że dane wyjściowe pasują do opisu etykiety. Na przykład, jeśli dźwięk zwierzęcia dla etykiety "hello" spełnia wspomniany procent, zwierzę rzeczywiście mówi "hello".
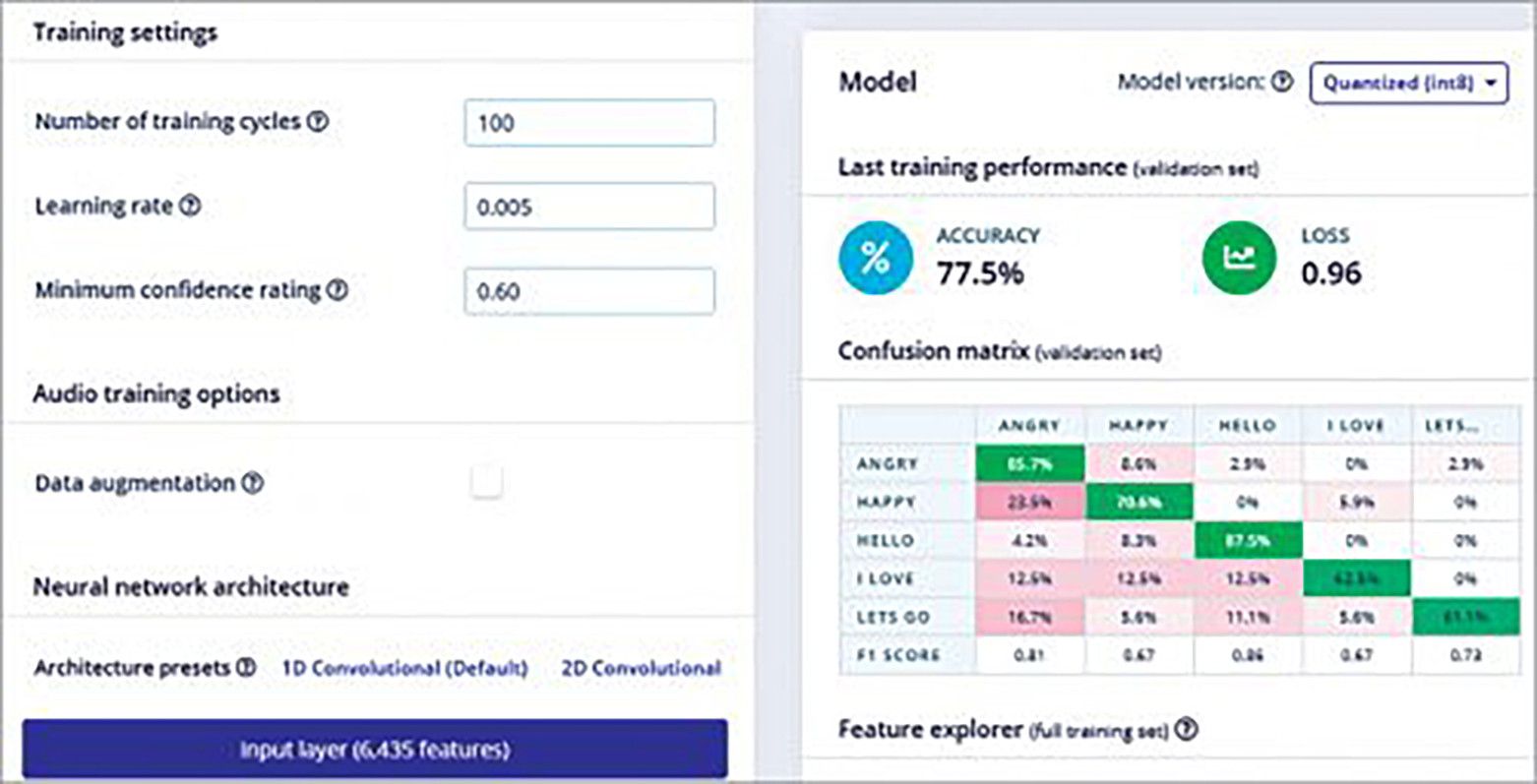
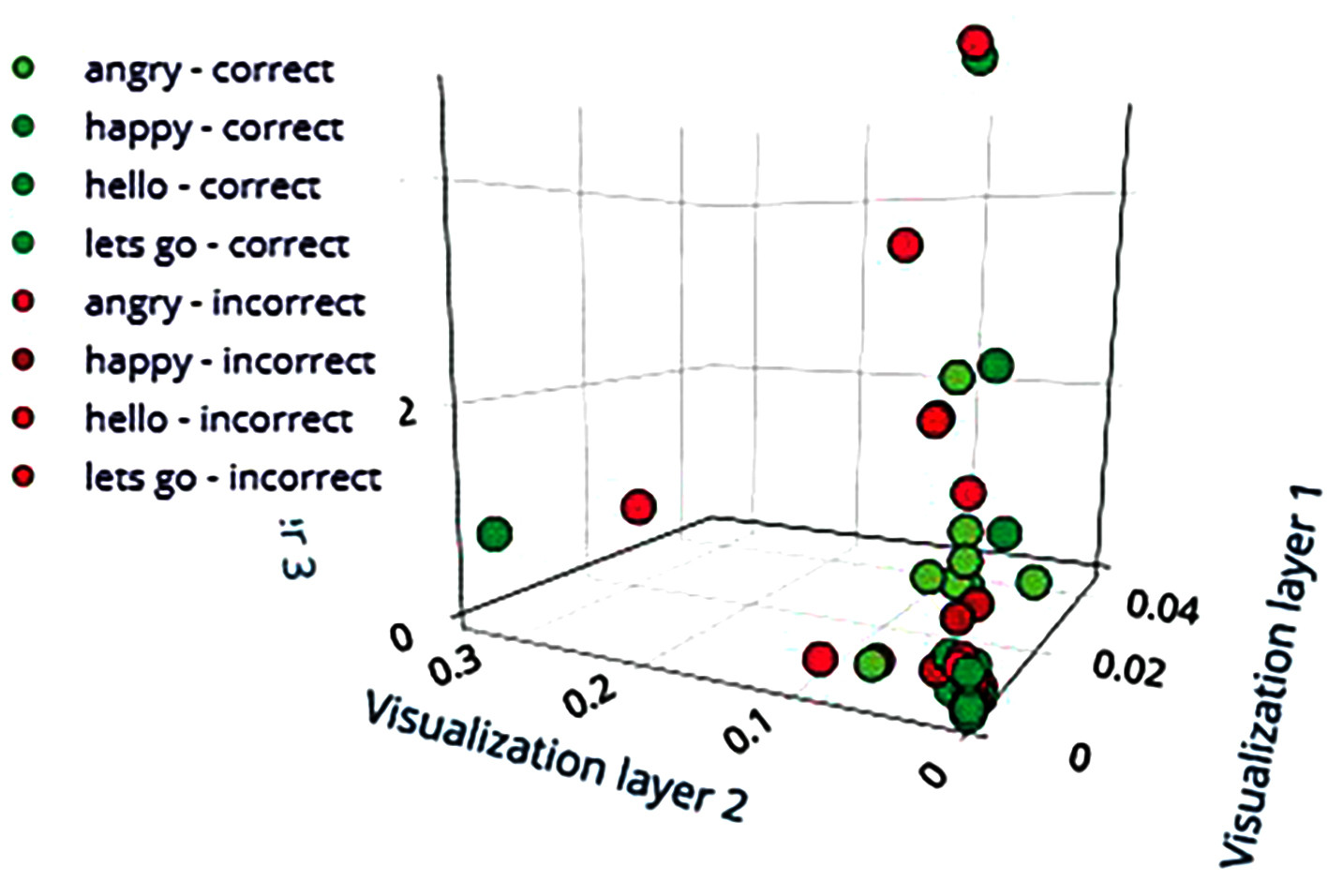
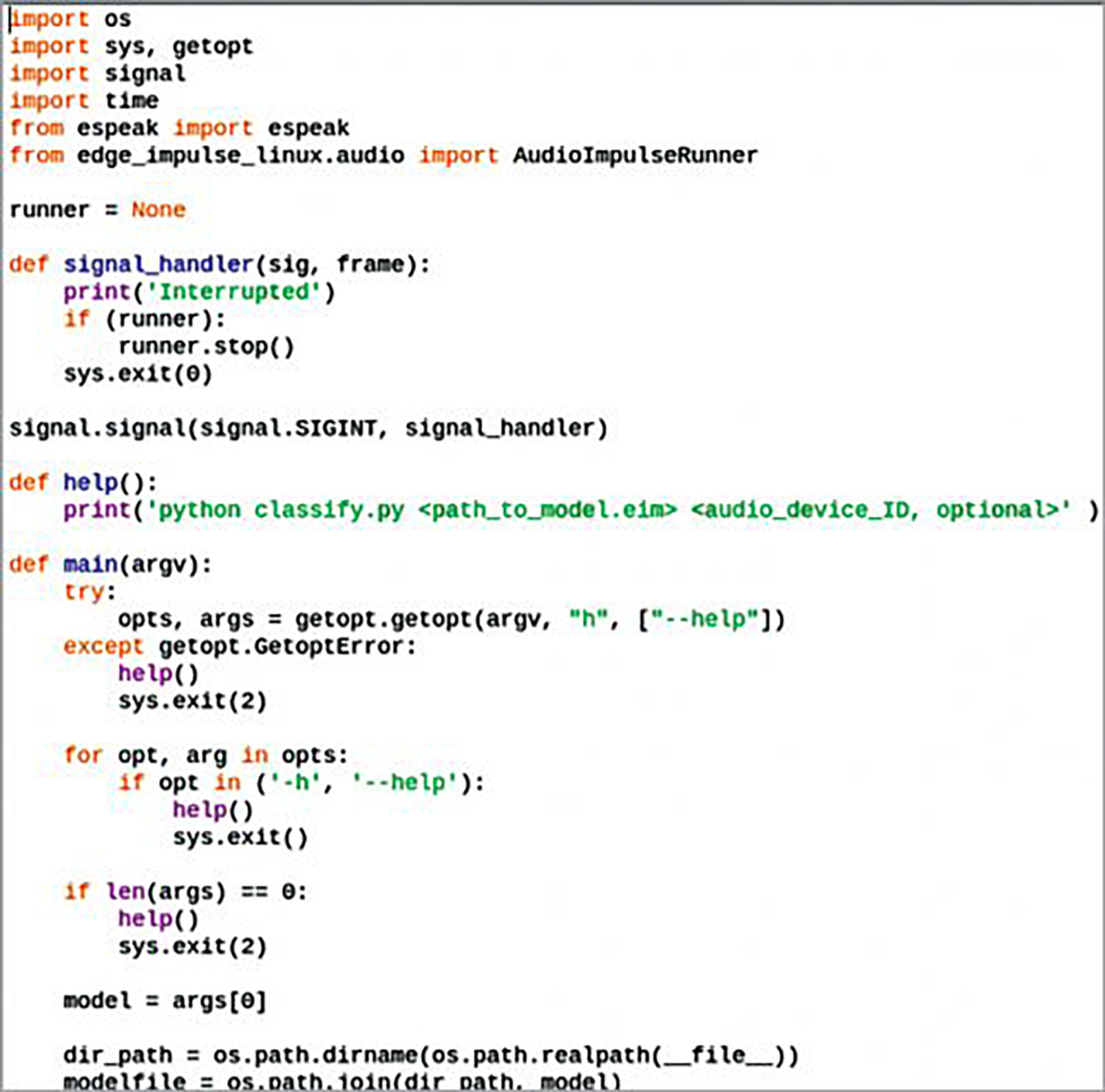
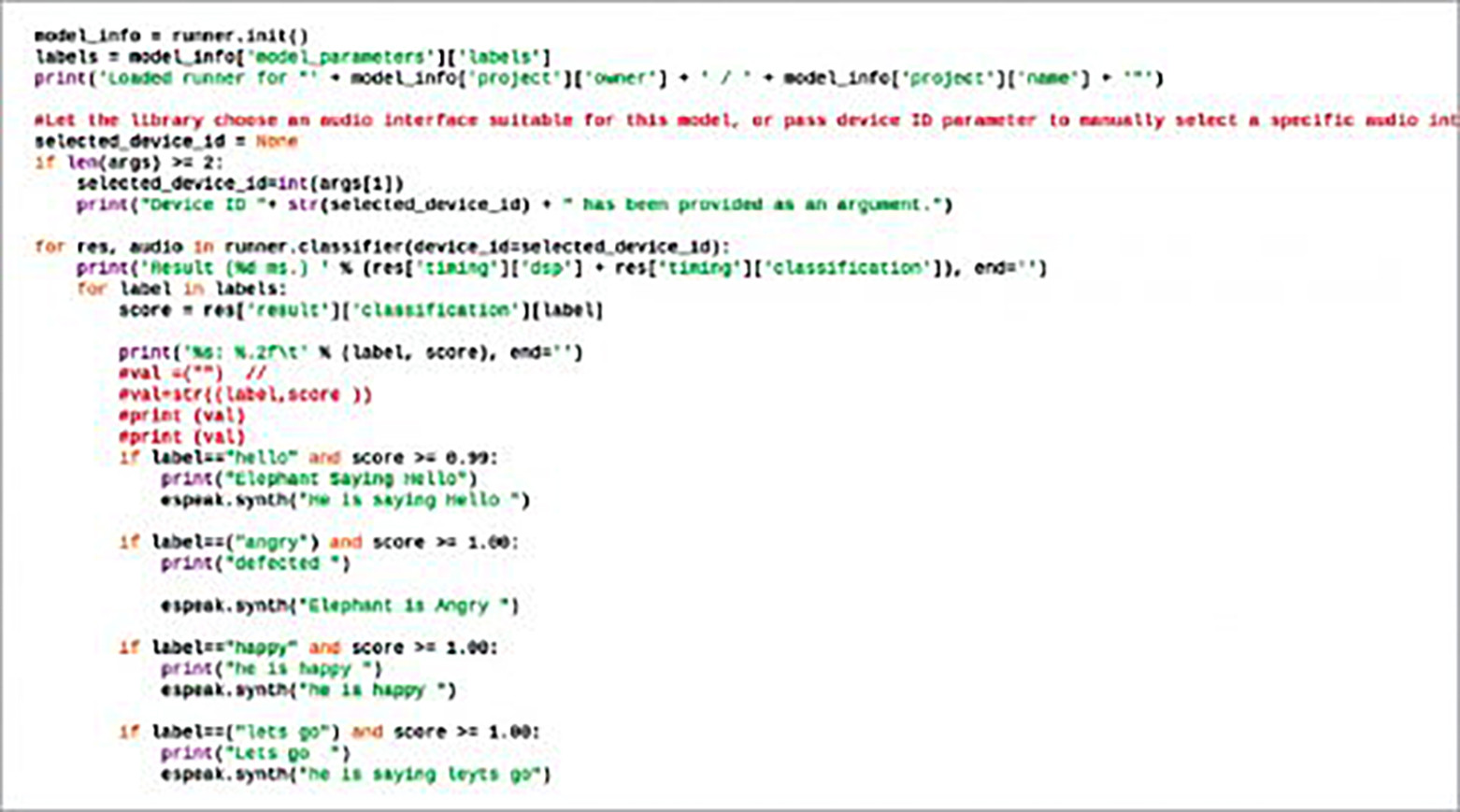
Testowanie
Pobierz plik modelu ML .iem, otwórz terminal i uruchom animal_translate.py, a następnie ścieżkę lokalizacji modelu ML. Wybierz zwierzę, powiedzmy słonia. Za każdym razem, gdy słoń wyda jakikolwiek dźwięk, model ML przechwyci go w czasie rzeczywistym i przetłumaczy to, co słoń mówi do Ciebie.

Gratulacje! Jest to prawdopodobnie pierwszy na świecie translator języka zwierząt i ptaków. Teraz można rozumieć język natury, a nawet wchodzić z nim w interakcję.
Ten artykuł został po raz pierwszy opublikowany online, możesz przeczytać go tutaj.